Join the MicroCenterOfficial Folding@Home Team: #257944
Comments
-
@teamtempest , You might want to check your logs, I investigated a sudden points drop a few days ago and found the GPU slot was no longer using cuda, but errored out and had reverted back to Opencl because the newer folding software required an Nvidia driver update. Updating the driver fixed the error and my points immediately went back to normal. Biofilms was one of the projects I was getting bad performance and low points on too until I fixed it.
-
Re: Too large WU/ too short deadline /no way to refuse

by nemric » Wed Dec 01, 2021 5:03 pm
Same problem here, my CPUs are smal (ATOM D525 and D2700) and recently my FAHclient download unit I can't achieve on 24/7 running computers, ETA is calculated over timeout date but this cause no problem to the client, it runs, for nothing...
I asked for downloading smaller WU but the best would be to adjust timeouts on CPU capabilities or giving arbitrary 2 or 3 more days...
I know these are very small CPUs but they are for fan-less/noise-less home servers and the purpose of FAH is to use free cpu time not to force users to buy big noisy machines to fold 24/7
for now, project 16969 and 16955 have a deadline really too short for me... (My 2 atom CPUs at least, the celeron G3220T without hyperthreading works great)
at this time, 21-12-01 , the D525 announce ETA 5.98 days, timeout 21-12-03 12:04, expiration date 21-12-05
Posts: 5
Joined: Tue Nov 30, 2021 7:56 pm
Re: Too large WU/ too short deadline /no way to refuse
by JimboPalmer » Wed Dec 01, 2021 5:51 pm
Let me be brutal to be honest.
A WU that is not returned or returned too late not only slows your WU, but it slows the entire project. The next generation cannot start until all of this generation is finished.
As such, there is no incentive for the developer to cater to slow CPUs. She/he want results as quick as they can get them. "Publish or Perish" is very real in Academia.
I can and do offer help to speed up marginal CPUs, but at some point, it is time to find a BOINC project where speed is not important.
Posts: 2412
Joined: Mon Feb 16, 2009 5:12 am
Location: Greenwood MS USA
Re: Too large WU/ too short deadline /no way to refuse
by nemric » Wed Dec 01, 2021 7:15 pm
Yes you're brutal !
I fold since 2004, I give free cpu time (and in some way, it's money) to this project for years !
The time I fold too large units is lost for science due to timeout limit that is too short, so don't assign so much work to small CPU ... If science don't need CPU's free time, it's time to say it now !
There are many posts here that talk about that, for PCs that are shutdown during the night, during weekend, and so on ... A lot of work is lost due to timeout and you claim that science need us !? science don't have time to wait for ongoing WUs but have the time to reassign the work that have been done up to 90% by a slow machine ? perhaps it will be assigned to a poor cpu again and again to have 90% + 90% .... of the work done but never published ?
You'd better optimize your process before asking me to upgrade my PC to work faster ! Science should not care about who have the biggest one !
"Publish or Perish" !? I have 3 PCs that work 24/7 for fah ... are they useless ? do you talk for science or for yourself ?
Posts: 5
Joined: Tue Nov 30, 2021 7:56 pm
Re: Too large WU/ too short deadline /no way to refuse
by v00d00 » Wed Dec 01, 2021 8:00 pm
nemric wrote:The time I fold too large units is lost for science due to timeout limit that is too short, so don't assign so much work to small CPU ... If science don't need CPU's free time, it's time to say it now !
"Publish or Perish" !? I have 3 PCs that work 24/7 for fah ... are they useless ? do you talk for science or for yourself ?
If you aren't making deadlines then it probably is time to deactivate those machines. It's just a matter of fact with FAH. Over time machines get old and if you don't upgrade they eventually don't meet deadlines and you are then damaging the project. Usually the project maintainers get around this by creating cores that no longer work on older hardware or won't use older optimisations. But users are expected to act responsibly and decommision when the time is right. CPU folding is a dying art nowadays unless you are fielding big systems with 32+ cores. You can generally do more for science with a cheap nvidia card that uses very little watts than with an old dual core cpu.
So it's up to you in the end. You can continue running something that is damaging the science of the project due to selfishness or just accept that the project moves forward and scales up with upgrades in technology, which in time, means older technology becomes obsolete. But the responsibility is yours, not ours.
***********
I will check the logs (if I can find them). The problem continues for the GPU (the CPU runs just fine). This has been consistent over the last few weeks; prior to now I only noticed one work unit ever that failed to complete due to timeout.
In the meantime I found this thread on the F@H support forum. It suggests that this problem is not rare.
I find the overall tone quite callous. "Damaging the science"? I'm not about to take pity on the poor academics who must "publish or perish". They're only damaging their own cause by handing out oversized work units, thereby delaying the result so very important to them.
I take the attitude that if the F@H client runs at all it should be responsible for using the resources available to it in a non-wasteful fashion. We are volunteers after all, donating time and money for free. If F@H no longer wants to use hardware "damaging to science" it can retire the clients capable of using them.
-
@teamtempest I was just trying to help with your GPU running slow... I suffered a similar slowdown and by going to the Nvidia website, downloading and installing the latest drivers for my GPU, I was able to get back the performance I expected. It seems the newest GPU folding software (which is downloaded and used automatically - no action required on your part) needed a newer GPU driver than I had. This change was rolled out by the F@H team starting mid-to-late November. I was able to find this information in the same F@H support forums where you found all the negative comments from others complaining about how awful the CPU based work unit assignments are.
You might want to try implementing this suggestion to see if it helps.
-
Oh, I found the logs but no convenient way to search them for "CUDA". No matter; I just installed the September 2021 driver from Nvidia. Now at least the GPU work units have the potential to be finished.
-
Not that they're actually finishing; just that for a while they show an estimated completion time less than the allowed time. They still don't finish, so it's all a waste. This is pointless and becoming increasingly annoying.
-
It's odd that I can get work units for the CPU that require four hours to finish and the time limit is four days, but it's rare to get a GPU work unit that starts out with even a minimal chance of finishing within the time limit. Something's off about the scheduling algorithm.
But they may be working on it. That GPU biofilm project came back again, which at 1% finished had a predicted finish time beyond what was allowed. So I lowered the available time it could have to work with the idea being that I don't care to donate resources to a project that used them so irresponsibly. But today I see the biofilm project has gone away, long before it's scheduled time out. It's been replaced by another project that should finish in time if I give it the resources it needs.
Maybe some project manager has a clue.
-
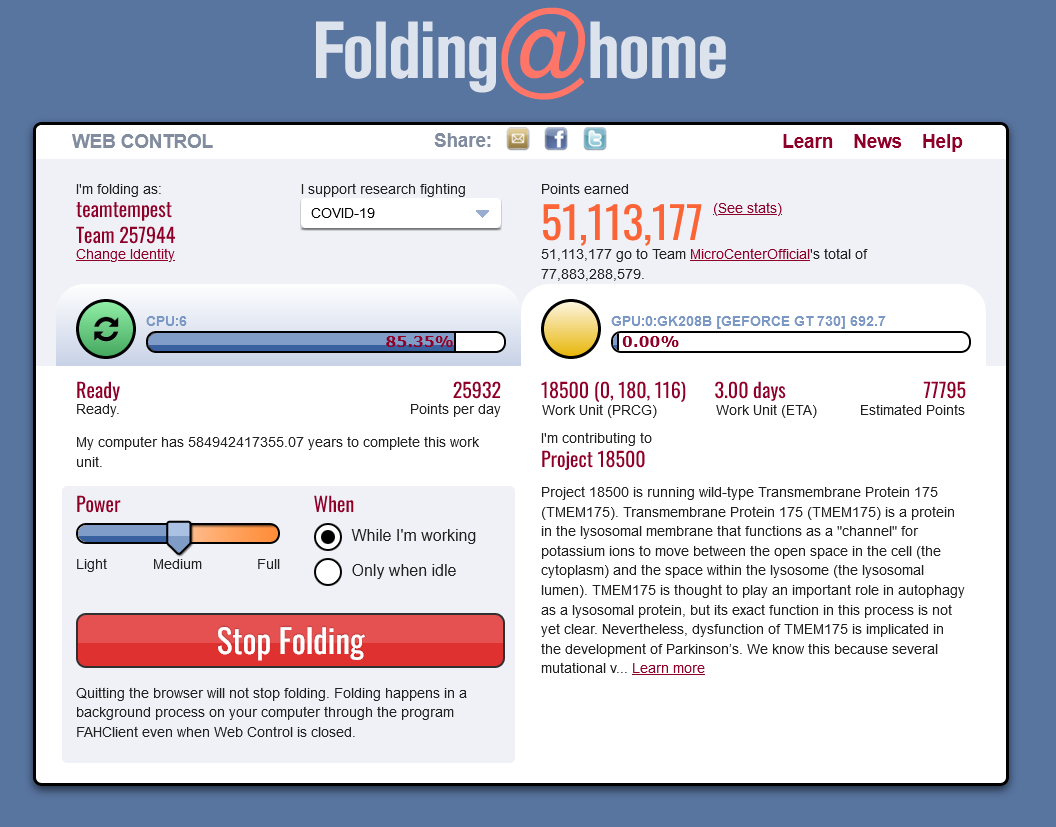
It's good to know I'm not going to run out of time on this one.
-
Having some more firewall issues at the moment, and the client seems to be having fun with math. 477M Points per day! I don't think so, FAH 🤣

-
Just started folding again. Is the 4080 better at folding than the 3090?
-
Yes, without a doubt.
Power cost per 1m points is also less than half for the 4080 vs 3090.














Categories
- All Categories
- 1 The Blog
- 1 What's Trending
- 8K The Community
- 3.2K General Discussion
- 146 New Members
- 873 Consumer Tech
- 234 Prebuilt PCs and Laptops
- 168 Software
- 33 Audio/Visual
- 54 Networking & Security
- 4 Home Automation
- 5 Digital Photography
- 14 Content Creators
- 30 Hobby Boards & Projects
- 84 3D Printing
- 83 Retro Arcade/Gaming
- 62 All Other Tech
- 449 PowerSpec
- 2.6K Store Information and Policy
- 151 Off Topic
- 63 Community Ideas & Feedback
- 619 Your Completed Builds
- 4K Build-Your-Own PC
- 2.9K Help Choosing Parts
- 328 Graphics Cards
- 335 CPUs, Memory, and Motherboards
- 145 Cases and Power Supplies
- 54 Air and Liquid Cooling
- 51 Monitors and Displays
- 93 Peripherals
- 69 All Other Parts
- 65 Featured Categories
We love seeing what our customers build
Submit photos and a description of your PC to our build showcase
Submit NowLooking for a little inspiration?
See other custom PC builds and get some ideas for what can be done
View Build ShowcaseSAME DAY CUSTOM BUILD SERVICE
If You Can Dream it, We Can Build it.

Services starting at $149.99